J’aimerais vous présenter à travers ce billet la notion de « modèles de données ». Cette notion débouchera naturellement sur le but premier que je me suis fixé: une introduction aux modèles de données orientées graphes et de l’une des excellentes bases de données qui en découle.
Vous trouverez en première partie un rappel sur ce qu’est un modèle de données, quels sont les modèles existants et ce à quoi ils peuvent nous servir. En deuxième partie, nous aborderons des exemples plus concrets à travers un survol rapide de la base de données orientée graphe, Neo4J.
Base de données
Une base de données, c’est un ensemble de données qui sont organisées dans le but de permettre une recherche d’information rapide.
Voilà ! C’est tout ! En fait, concrètement une base de données c’est plutôt abstrait ! Et en même temps, je crois qu’on pouvait s’y attendre avec un terme tel que « base de données » qui couvre, pour être sincère, un très large domaine. Il est donc normal que sa définition soit limitée. Afin de se tourner vers quelque chose de plus « concret », il faut regarder du côté des modèles de base de données et des systèmes de gestion de bases de données qui les supportent.
Modèles
Afin de répondre à différents besoins et à différentes problématiques, il existe de nombreux modèles de bases de données. Chacun d’entre eux apporte sa propre philosophie et concepts pour stocker et retrouver de l’information. Comme analogie, on peut comparer un modèle de donnée au paradigme d’un langage de programmation.
Quelques modèles de base de données:
relationnelle
multi-dimensionnelle
document
triple-store
graphe
temps-réel
Certains modèles se recoupent, soit parce qu’il sont basés sur les mêmes idées, soit parce qu’ils sont construit sur la même base théorique que d’autres ou encore parce qu’il s’inspirent de leur(s) mode(s) de stockage ou de traitement de l’information.
Modèle conceptuel
On peut en principe définir tout modèle de données par un Modèle Conceptuel de Données: le MCD. Celui-ci permet de décrire un ensemble d’entités et les relations qu’elles entretiennent. Le schéma physique – MPD – pour Modèle Physique de Données décrit quant à lui la manière dont est structuré l’information. Le MPD peut être abstrait ou concret selon les modèles. Par exemple le modèle relationnel impose la définition d’un schéma concret défini par ses tables, le modèle orienté document, plus souple, permet de structurer en partie l’information et finalement le modèle orienté graphe se structure de lui même par ses relations.
Je vous avais promis du concret, c’était bien concret… en théorie. Passons donc à la suite, le système de gestion de bases de données.
Système de gestion de bases de données
Rappel
Le système de gestion de base de données, que nous abrégeons DBMS pour « Database Management System » peut-être vu comme l’implémentation d’une base données. Il s’agit d’un ensemble de programmes et d’outils permettant le fonctionnement de la base de données, son stockage et son traitement. Voilà enfin quelque chose de concret.
Composition
Grossièrement un DBMS et composé d’un moteur de base de données composé lui-même par:
Un moteur de traitement: qui a une prise en charge d’un ou plusieurs langage(s) de requêtes permettant de créer, lire, de mettre à jour et de supprimer de l’information – CRUD – Create Read Update Delete et éventuellement une gestion des transactions ACID
Un moteur de stockage permettant la persistance des données en mémoire ou sur disque
Transversalement à ces systèmes viennent s’ajouter:
la gestion des droit utilisateurs
les interfaces utilisateurs – visuelles ou en ligne de commande – permettant leur gestion
les clients et les API permettant leur manipulation par programmation.
Le modèle relationnel
Les RDB – Relational Database – sont implémentées par les RDBMS: « Relational Database Management System ».
Structure
A partir de la définition d’un schéma concret et statique, les bases de données relationnelles traitent l’information sous forme de données structurées par des sortes de conteneurs qui sont appelés tables. Les tables tirent simplement leur nom du fait qu’elles organisent les données sous forme de lignes et de colonnes. Chaque ligne – row – est un tuple ordonné dont les composantes sont définies par les colonnes de la table et représente totalement ou partiellement, une entité ou une action.
Un peu de théorie
Mathématiquement une table est un ensemble et les lignes, éléments de cet ensemble, sont des tuples. La relation quant à elle est un ensemble de tuples dont les composantes font respectivement référence à une composante d’un tuple d’un autre ensemble. Une relation 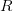 entre
entre 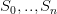 est donc le sous-ensemble du produit cartésien des ensembles [1]
est donc le sous-ensemble du produit cartésien des ensembles [1]
Ce n’est pas très clair ? Rentrons un peu dans les détails.
Voici notre modèle relationnel
Un ensemble 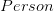 avec pour éléments des tuples définis par la structure suivante
avec pour éléments des tuples définis par la structure suivante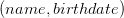
Un ensemble 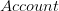 avec pour éléments des tuples définis par la structure suivante
avec pour éléments des tuples définis par la structure suivante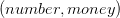
Un ensemble 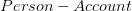 avec pour élément des tuples définis par la structure suivante
avec pour élément des tuples définis par la structure suivante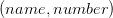
Mathématiquement
est défini par  avec
avec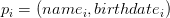
est défini par 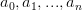 avec
avec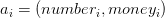
est défini par 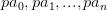 avec
avec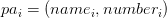
Soit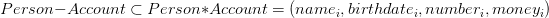
Exemple instancié
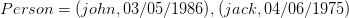
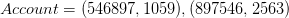
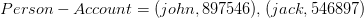
On observe que l’ensemble est une relation mathématique entre et car il est sous ensemble du produit cartésien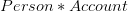 .
.
Donc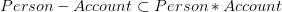 .
.
Ainsi il est possible d’effectuer entre les tables toutes les opérations possibles sur des ensembles comme par exemple, l’union – FULL OUTER JOIN -, le produit cartésien – CROSS JOIN – l’intersection – jointure interne INNER JOIN –, etc. Afin d’optimiser la recherche et le croisement d’informations, le modèle relationnel dispose aussi par ailleurs des notions de clés et d’indexation.
Pourquoi tout ces détails ? C’est pour distinguer correctement les RDB des bases de données orientées graphe – GDB pour Graph Database. Alors que les RDB représentent la relation entre des ensembles de données, les GDB représentent la relation directement entre les données.
Pourquoi ce modèle ?
Pour les opérations sur les ensembles de données. Ce type de base permet de recouper facilement des lots complets de données. Sa structure statique lui permet toutes les optimisations possibles pour réduire les coût mémoire et temps et permet notamment d’ériger des contraintes et une intégrité des données très forte à condition, bien sûr, que le modèle soit correctement conçu.
Le modèle orienté document
Les noms de MongoDB ou de CouchDB ne vous seront surement pas inconnus. Ces dernières années, on a pu remarquer l’explosion de l’utilisation des bases de données orientées document. Conçues pour la gestion de données semi-structurées, elle permettent de présenter des instances – les documents – qui semblent proche de la notion d’objet.
Structure
Semi-structuré, c’est une de ces forces principales. Grâce à sa flexibilité, ce modèle permet de gérer des collections de documents aux formats hétérogènes. Les documents eux aussi flexibles peuvent se voir ajouter ou retirer une propriété, modifier leur type grâce au côté dynamique et au « latent typing ». Si l’on devait comparer une base de données orientée document à un système de type, on pourrait dire qu’il s’agit de typage dynamique.
Il est cependant bien sûr possible de structurer en partie l’information afin d’optimiser (indexation par exemple), ou de contraindre.
Même si ce modèle a de nombreux avantages, il manque une notion forte de relation entre les données car celles-ci sont stockés par collection, de manière déconnectées. Ainsi il convient généralement d’user de la redondance et de l’encapsulation de données pour traiter des relations de compositions. Voir ci-dessous:
|
{ { |
Ou encore d’index pour les relations d’agrégations, comme ici:
|
{ { { |
Dans le cas des relations bi-directionnelles il convient de penser à maintenir la cohérence entre les documents. Reprenant l’exemple ci-dessus, si jak et rob ne se parlent plus pour une sombre histoire de meilleures pratiques quant à la position des accolades dans un code source, il faut d’une part, supprimer l’identifiant correspondant à rob dans les amis de jak et d’autre part, supprimer l’identifiant correspondant à jak dans les amis de rob. Cette maintenance a un coût en performance et en lisibilité.
Dans le cas d’un modèle relationnel, les relations bi-directionnelles sont gérées intrinsèquement par la structure même de la base de données. Cette relation étant représenté par une table de liaison.
Pour conclure, je dirais que le fait que la structure soit optionnelle et libre nécessite de très bonnes connaissances sur comment définir un modèle de données, sans quoi il est difficile d’en maximiser les performances sans impacter d’autres facteurs.
Pourquoi ce modèle ?
En dehors de toute considération technique, le modèle orientée document tend à pallier des problématiques très actuelles. Il répond au besoins d’agilité et de flexibilité qui sont aujourd’hui de plus en plus courants. Son mode de stockage permet aussi d’assurer la gestion et le traitement de données de façon massive, de distribuer l’information entre différentes machines et de permettre la fouille de données intensive.
Le modèle orientée graphe
Le modèle orienté graphe n’est pas nouveau car il reprends un modèle nommé « network model » créé dans les années 70 par Charles Bachman au sein du consortium CODASYL [2] – qui a par ailleurs conduit à la création du langage COBOL.
On peut aussi considérer que les modèles de représentation des connaissances, les thésaurus et ontologies définis par différents formats comme OWL – Ontology Web Langage – et RDF – Resource Description Framework – sont des modèles de données orientés graphe spécialisés.
Ce modèle s’appuie sur la notion de graphe au sens mathématique pour stocker et traiter l’information.
Structure
Comme son nom l’indique, ce modèle structure les données sous forme de graphe. C’est à dire un ensemble de nœuds qui peuvent être reliés entre eux par des arcs. Voici un exemple de graphe:

Les nœuds représentent les entités, ils peuvent être comparés aux documents du modèle orientée document. Un nœud est défini par un ou plusieurs labels, une sorte de type si l’on peut dire, et comporte des propriétés sous forme de paires clé / valeur.
Les labels – étiquettes – permettent de regrouper de manière transversale les nœuds dans un ou plusieurs ensembles. Cela permet de requêter un ou plusieurs label de la même façon que l’on le ferais sur des collections dans le modèle orienté document. Ci-dessous, vous pourrez voir quatre nœuds, dont deux étiquetés « Person » et deux étiquetés « Animal »:

Les arcs quant à eux spécifient la nature de la relation entre deux nœuds de manière uni-directionnelle. Ils peuvent aussi parfois comporter des propriétés pour différencier la relation ou spécifier son degré ou sa nature (par exemple un ordre).
Exemple avec Neo4J:

|
MATCH (n1)-[r]->(n2) RETURN n1, r, n2 |
|
╒═════════════════╤═══════════╤═══════════════════╕ |
Pour obtenir une relation bidirectionnelle explicite, il suffit d’avoir deux arcs de relation complémentaires uni-directionnels dans un sens, puis dans l’autre. Ce qui exige bien sûr une maintenance pour la cohérence des relations mais de coût moindre. Par contre si vous souhaitez une relation bidirectionnelle implicite, il suffit de créer un arc dans un sens ou dans l’autre, la requête sera alors la seule à déterminer le fait que la relation peut-être traversable dans les deux sens.
Exemple avec Neo4J:
|
MATCH (n1)–[r]–>(n2) |

Pourquoi ce modèle ?
Le but premier de ce modèle est de représenter « le monde réel » non plus sous un ensemble de données isolées mais de données interconnectés. Cela permet de définir plus facilement certaines structures tel que les thésaurus et les ontologies. En effet, le graphe représente bien les domaines variablement structurés [3] comme par exemple les réseaux sociaux devant maintenir les relations entre les personnes, l’univers musical et ses nombreux genres de musiques qui s’entremêlent, etc.
L’avantage de ce modèle, c’est que les relations entre les nœuds sont directes, on dit que ce modèle permet d’avoir, du moins en théorie, « une contiguïté des données sans index ». L’expression communément admise en anglais dit que ce modèle est « index-free adjacency ». Je précise en théorie parce que tout dépend du moteur de stockage et de traitement utilisé. En principe, pas de table d’index, pas besoin d’aller jeter un œil aux index pour faire une liaison entre deux données, un nœud pointe directement sur un autre par le biais de la relation.
Ce principe lui confère deux propriétés remarquables:
- L’opération pour trouver une relation a un coût théorique de
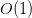 – une seule opération
– une seule opération - Cette opération garde le même coût quelque soit la quantité de données contenu dans le graphe
Par cela, le modèle orientée graphe est très adapté pour les recherches en profondeur dans les arbres de données, tandis que les modèles relationnels ou orientés document provoquent une « explosion combinatoire » due au nombreuses « jointures » nécessaires pour obtenir le même résultat. Explosion combinatoire qui est proportionnelle à la quantité des données présentes dans les ensembles à relier, même si bien sûr, les tables d’index permettent de réduire ces coûts. Donc pour être sincère j’exagère un peu avec le terme d’explosion combinatoire car le coût de recherche dans une table d’index – qui par définition est triée – est d’environ [4] [5]. Ce qui reste, tout de même supérieur à dans le cas où l’on doit effectuer de nombreuses jointures.
Si je précisais plus haut que le coût de est théorique, c’est parce qu’il dépend fortement du moteur de stockage et de traitement utilisé. En effet, certaines bases de données orientées graphe ont un moteur de stockage et de traitement natifs, d’autre on un moteur de stockage relationnel avec un moteur de traitement optimisé pour le traitement de graphes, certains un moteur stockage de graphe natif et un moteur de traitement non natif, etc. En fait, certaines d’entre elles sont basés sur le modèle relationnel ou document… en partie ! [6]

Bien sûr, le moteur de stockage va cependant être toujours optimisé de manière à rendre compte des meilleurs performances possibles pour effectuer des requêtes de type « parcours de graphe », sans quoi ce type de base n’aurait que peu d’intérêt, hormis la sémantique du langage de requête.
Certains moteurs de traitement ont aussi une philosophie simple en ce qui concerne le traitement des requêtes: filtrer au plus tôt. C’est à dire qu’à chaques étape de calcul, lorsque les noeuds sont traversés, le moteur va appliquer les éventuels filtres – donné par la requête utilisateur – afin de diminuer la charge totale de données à traiter. Ces filtres ont pour effet de diminuer la complexité de la requête et donc les coûts en terme de traitement. [7]
Cas d’école
L’ontologie FOAF [8] est un bon exemple pour comprendre ce que ce modèle peut apporter. L’ontologie FOAF – Friend Of A Friend – est une ontologie décrivant des personnes et les relations qu’elles entretiennent.
Voici notre schéma de base de données relationnelle

Remarque: la table friend représente une relation bidirectionnelle, sans sens préférentiel. On considère donc que si une personne A est ami avec une personne B, alors forcément B est ami avec A.
Je souhaite trouver qui est ami avec jak:
|
SELECT p1.firstname FROM person jak UNION SELECT p1.firstname FROM person jak |
On cherche les personnes liés à jak dans la table friend. Que jak soit référencé par la clé étrangère PersonA_id ou PersonB_id nous importe peu, car il s’agit d’une relation bidirectionnelle sans sens préférentiel.
Vous remarquerez que l’écriture est non seulement verbeuse, mais de plus que la requête est assez coûteuse en terme de plan d’exécution.

Les jointures auront tendance à faire augmenter le temps d’exécution selon la quantité de données présente dans les tables, tout comme la recherche de la personne dont on souhaite connaître les amis, ici ceux de jak.
Avec un modèle orienté graphe, trouver les amis de jak ou revient à simplement traverser le graphe.
|
MATCH (jak:Person {firstname:“jak”})–[:FRIENDS]–(p) |
La requête est simple, claire et concise. Et voici le plan d’exécution :

On voit qu’il y a une recherche par label, le filtre de recherche de la personne ayant pour prénom « jak » est appliqué directement (filtrage au plus tôt), les noeuds associés par la relation FRIENDS sont étendus et le résultat est produit.
Ici nous avons vu un exemple très simple où il s’agit d’une recherche d’amis à un seul niveau de profondeur. Maintenant, imaginez chercher les amis des amis de jak ? ou encore le nombre d’intermédiaire entre jak et eva ? (comme on retrouve dans LinkedIn). La complexité de telles requêtes tant au niveau sémantique que algorithmique et la perte de performance qu’elles induisent se fera ressentir au niveau d’une simple base de données relationnelle. Alors que pour une base de données graphe, on est dans une logique de simple navigation à travers les noeuds, et d’agrégations des résultats de ces navigations.
Bien sûr cet avantage est fortement lié au type de requête. S’il s’agit d’une requête de type « parcours de graphe » on profitera des pleines capacité de ce type de modèle. Par contre s’il s’agit d’une requête de type « opération sur ensembles » on obtiendra, en théorie, au maximum les mêmes performances qu’une base de données relationnelle.
Dans sa philosophie, le modèle orienté graphe, remet au centre le concept de relation. La relation devient ainsi un objet de premier ordre aussi important, voir même plus, que la donnée elle-même. Par ce fait, ce modèle est ainsi très bien adapté à la représentation des connaissances, la modélisation de réseaux de neurones, etc.
Pour finir, il partage au moins un atout en commun avec le modèle orienté document : l’information peut-être facilement distribuée, c’est à dire disséminée entre plusieurs systèmes d’informations. Il permet aussi, en principe, de traiter les requêtes de manière massivement parallèle en parcourant simultanément plusieurs chemins du graphe, les résultats étant ensuite agrégés. Il existe notamment certaines implémentations d’algorithmes très puissants pouvant fonctionner directement sur ces modèles.
Comment requêter les données ?
Modèles différents signifie langages de requêtes différents. Les bases de données orientées graphe proposent, selon les distributeurs, différents langages de requêtes [9] :
SPARQL – Déclaratif
Cypher – Déclaratif
Gremlin – Déclaratif / Impératif
SPARQL au départ conçu pour requêter les modèles de connaissances au format RDF est sans doute celui ayant le plus de ressemblance avec SQL, mais il ne faut pas s’y tromper, la logique reste très différente.
Cypher quant à lui se rapproche du ASCII Art pour représenter les requêtes au sein d’un graphe. Ce design lui confère l’avantage d’être très intuitif, facile à apprendre et à utiliser. Il est inspiré à la fois de SQL notamment au niveau de mot-clé WHERE et ORDER BY ainsi que de SPARQL, de Haskell et de Python pour ce qui concerne le pattern matching et son aspect déclaratif et fonctionnel.
« Being a declarative language, Cypher focuses on the clarity of expressing what to retrieve from a graph, not on how to retrieve it. »
Gremlin quant à lui, est un « mini-langage », spécifique au requêtage sur les graphes, utilisable dans divers contextes – parfois autres que celui concernant les bases de données – et présent dans un ensemble de langages de programmation « nativement » [10].
Si vous souhaitez faire le tour d’une véritable base de données orientée graphe, je vous invite à lire la deuxième partie, Bases de données graphes – Neo4J.
Références :
[1] A Relational Model of Data for Large Shared Data Banks : http://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
[2] CODASYL : https://en.wikipedia.org/wiki/CODASYL
[3] Oreilly – Graph Databases – p.19 : https://www.oreilly.com/catalog/errata.csp?isbn=9781491930892
[4] How MySQL uses indexes : https://dev.mysql.com/doc/refman/5.7/en/mysql-indexes.html
[5] Binary search tree : https://en.wikipedia.org/wiki/Binary_search_tree
[6] An overview of Graph database query languages : https://developer.ibm.com/dwblog/2017/overview-graph-database-query-languages/
[7] Cypher – Query Tuning : https://neo4j.com/docs/developer-manual/current/cypher/query-tuning/
[8] FOAF Ontology : https://en.wikipedia.org/wiki/FOAF_(ontology)
[9] Neo4J Developer manual : https://neo4j.com/docs/developer-manual/3.3/
[10] Gremlin repository : https://github.com/tinkerpop/gremlin